Genvorhersage/Gen-Annotation
Unter diesen Begriffen versteht man das a priori Auffinden von Genen innerhalb einer Nukleotidsequenz anhand von typischen Mustern wie beispielsweise Promotor, oder Start- und Stopsignale von Introns.
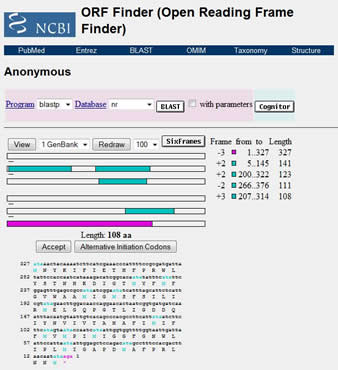
...ist ein Sequenzanalyse-Tool, dass auf der Homepage des NCBI bereitgestellt wird. Es sucht nach offenen Leserastern (ORF = open reading frame, bestehend aus Start-Codon + Folge von 3-Nucleotid-Codons + Stopp-Codon) in einer gegebenen DNA-Sequenz. Auf diese Weise kann man in einem neu sequenzierten DNA-Stück nach potentiellen proteincodierenden Bereichen suchen.
Innerhalb der sechs möglichen Leseraster (3 pro Einzelstrang) sucht der Algorithmus jeweils die längsten ORFs, wobei man eine Mindestlänge für angezeigte ORFs definieren kann. Da sich diese über Start- und Stoppcodons definieren, ist es essentiell, dass der richtige Code verwendet wird (in Mitochondrien z. B. codiert AUA statt AUG für Start). Dieser kann unter 16 verschiedenen Möglichkeiten ausgewählt werden. Das Ergebnis wird in Form von grünen Balken unterschiedlicher Länge angezeigt; der längste Balken ist ein guter Kandidat für ein mögliches Gen. Er kann zur weiteren Analyse angewählt werden (per Mausklick --> Farbe ändert sich zu lila); gleichzeitig werden Nucleotid- und Aminosäuresequenz angezeigt. Über BLAST kann man in einem weiteren Schritt die Sequenz mit Proteindatenbanken abgleichen, um so das Gen zu identifizieren.
Diese sehr basale Anwendung führt einen statistischen Test durch und beurteilt die Wahrscheinlichkeit, dass eine DNA-Sequenz für ein Protein codiert. Nach dem Einfügen einer Sequenz (FASTA-Format) wird ein Wert samt Beurteilung ausgegeben. Es gibt drei Möglichkeiten:
> 0.95 --> Sequenz ist wahrscheinlich codierend,
< 0.74 --> Sequenz ist wahrscheinlich nicht codierend,
0.74 < x >0.95 --> unsicher, ob die Sequenz codierend ist oder nicht.
Eine Einschränkung besteht darin, dass nur codierende Regionen mit einer Mindestlänge von 200 Basen zuverlässig bewertet werden können. Viele eukaryotische codierende Sequenzen, die um einiges kürzer sind, werden somit nicht erfasst.
Literatur:
Fickett, J. Recognition of protein coding regions in DNA sequences. Nucleic Acids Res. 10 (1982), pp. 5303–5318, PMID: 7145702